
Introduction
For a variety of security reasons, obfuscating code is a best practice for mobile app developers. Legitimate app developers use obfuscation to protect intellectual property and prevent attacks against their code, and malware providers use it to hide malicious capabilities. Not surprisingly, in the cat-and-mouse game of cybersecurity, this creates a compelling need for deobfuscation techniques too. For example, Zimperium’s award-winning zLabs mobile research team is always looking for (or helping create) advanced deobfuscation tools to better analyze the true intentions and capabilities of potentially malicious mobile apps.
This blog introduces one such tool, a deobfuscation framework called SATURN [1], jointly developed by Peter Garba (Thales) and Matteo Favaro (Zimperium). The contents of the paper have been presented at the 3rd International Workshop on Software Protection (SPRO 2019) held in London on November 15th and co-located with the 26th ACM Conference on Computer and Communication Security.
What follows is not meant to be a complete compendium of existing obfuscation and deobfuscation techniques, but rather an overview of the evolution of the obfuscation approaches, a brief explanation of the common static analysis techniques, a description of the proposed tool SATURN and a discussion on its possible improvements. For a detailed explanation of the project the reader is invited to consult the full publication at the following arXiv link: SATURN.
Paper abstract
The strength of obfuscated software has increased over the recent years. Compiler-based obfuscation has become the de facto standard in the industry and recent papers also show that injection of obfuscation techniques is done at the compiler level. Finding a generic approach for deobfuscation and recompilation of obfuscated code based on the LLVM compiler suite is at the core of this research. Binary code can be lifted back into the compiler intermediate language LLVM-IR and it’s possible to recover the control flow graph of an obfuscated binary function with an iterative control flow graph construction algorithm based on compiler optimizations and SMT solving.
The mentioned approach does not make any assumptions about the obfuscated code, but instead uses strong compiler optimizations available in LLVM and Souper Optimizer to simplify away the obfuscation. The experimental results show that this approach can be effective to weaken or even remove the applied obfuscation techniques like constant unfolding, certain arithmetic-based opaque expressions, dead code insertions, bogus control flow or integer encoding found in public and commercial obfuscators.
The recovered LLVM-IR can be further processed by custom deobfuscation passes that are now applied at the same level as the injected obfuscation techniques or recompiled with one of the available LLVM backends. The presented work is implemented in a deobfuscation tool called SATURN.
Motivating example
The following snippets of code are showing the motivating example introduced by the paper, specifically the input C source code, the output LLVM-IR code obtained by SATURN and the reimplementation of the output as a C source code.

In Figure 1, we can observe that the example uses the FOR and SPLIT anti dynamic symbolic execution tricks explained in [12] and a common mixed boolean arithmetic opaque predicate to guard an XOR operation.
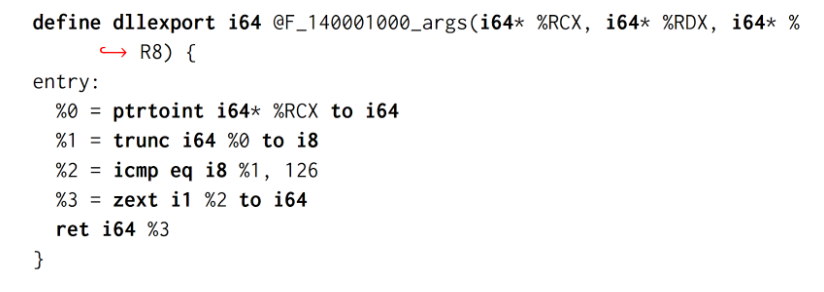
In Figure 2, we can see that the LLVM-IR contains the deobfuscated code with the FOR, SPLIT and MBA expression tricks removed. It’s also worth noting how the function signature has been successfully recovered (the RDX and R8 registers are now unused).

For an easier comparison with the original C source code, in Figure 3, we can see a reimplementation of the deobfuscated LLVM-IR.
Obfuscation evolution
In the past few years, the major obfuscation products moved from working at the binary level to being applied at the source code or compiler intermediate representation level. The main reason for this transition resides in the simplicity of the implementation of the obfuscation passes, that now can be integrated in a generic way on an intermediate language like LLVM-IR and at the same time be compatible with all the source code languages supported by an LLVM-based compiler.
Working at the binary level, instead, requires the obfuscation tools to deal with problems like disassembling [2], function boundaries recovery and reconstruction of a working binary, that are known to be hard to solve
Open source tools like Obfuscator-LLVM [3] or ADVObfuscator [4] were game changers in the Android and iOS landscape since their release and gave a boost to a huge number of commercial obfuscators based on LLVM like: strong-code [5], EPONA [6], BitGuard [7], iXGuard [8] and many custom forks [9] more or less legally integrated by custom Android protectors.
The desktop protectors underwent this transition some years before the mobile world, but it’s with the evolution of the Android and iOS DRM solutions that the approach has been widely adopted even by less knowledgeable parties and this called for proper analysis tools, working at the same conceptual level, to be developed.
Static analysis approaches
The research and academic community involved in the software protection world is constantly developing new attack and defense techniques, with some becoming state of the art approaches to defeat the most common obfuscation tricks. The most frequently used static analysis techniques can be summarized as follows.
Symbolic deobfuscation
Relies on an interleaving of symbolic and concrete execution (also called concolic execution) to explore the control flow graph of an obfuscated function. Its power comes from the capability to treat the obfuscated expressions symbolically, meaning that the function inputs, registers or memory buffers can be represented as mathematical variables. This enables the attacker to evaluate, simplify or solve the obtained expressions, leading to a better exploration of the obfuscated function and, hopefully, to a simplified version of the code. A good example of symbolic deobfuscation has been the attack against Tigress [10] described by Quarkslab [11].
The major complication of the described technique is the path explosion problem, which, coupled with hard-to-solve constraints, is the most efficient anti-dynamic symbolic execution trick as described in several papers [12].
Pattern matching
Although pattern matching cannot be considered a complete technique on its own, during the years many deobfuscation tools have been partially or entirely based on the matching and substitutions of patterns. To be precise pattern substitution is also a common compiler pass, more commonly named peephole optimization pass. The whole idea is to simplify expressions or subexpressions with known substitution rules like: A xor A == 0. A good example of pattern matching simplification applied to the IDA Pro microcode representation can be observed in this blogpost [13].
The major drawback of pattern matching is that writing many generic patterns can be tedious and error prone, hence why super-optimization tools aided by SMT solvers like Souper [14] or STOKE [15] are being researched and integrated as a compiler pass.
Program synthesis
Even if the original goal of program synthesis is to construct a program that provably satisfies a given high-level formal specification, it also seemed to perfectly fit the deobfuscation problem. The main idea is to start with a symbolic expression or sequence of instructions, use an emulation engine to obtain a set of input/output pairs and feed the data to an oracle responsible for synthesizing the semantic of the obfuscated code. The synthesis techniques can differ from tool to tool and can be more or less precise or performant.
As an example the Souper optimizer relies on different synthesis methods for the synthesis of the constants; Syntia [16] relies on a Monte Carlo Tree Search approach coupled with a base generative grammar to its synthesis-based deobfuscation step. Worth mentioning is the Drill&Join [17] algebraic synthesis approach that has been used to attack mixed boolean arithmetic expressions obfuscation and weaken some types of opaque predicates [18].
The major issues with program synthesis are usually deemed to be the synthetisation of the constants and the performance impact when dealing with semantically complex sequences of instructions.
Abstract interpretation
The major concrete application of abstract interpretation is formal static analysis, which consists in the automatic extraction of information about the possible executions of a computer program relying on the definition of different abstraction domains and semantics. In an optimizing compiler it can be found as a step to prove if a transformation or optimization is safely applicable to the underlying intermediate representation.
Its reliance on the semantic information of the analyzed code is heavily in contrast with the pattern matching deobfuscation approach, which is instead based on the syntactic information. In fact a sequence of instructions may be reshaped using a different syntax or order while preserving its semantic and effectively breaking the pattern-based approach if the pattern is unsupported, but leaving the abstract interpretation approach unaffected. A brilliant example of control flow deobfuscation via abstract interpretation is given by this Ghidra plugin [19] based on three-values abstraction (a bit can have 3 values: 0, 1 and ½ representing a bit of an unknown value).
The main complication with the usability of abstract interpretation as a deobfuscation method is the automatic definition of the abstraction and semantic domains that fit the analysis of the underlying obfuscated code.
Summary
From what is written above, we can clearly see that each of the mentioned techniques is particularly suited to solve some problems, but also presents some limitations when faced with others. The continuous evolution of the obfuscation and deobfuscation approaches resembles in fact a cat-and-mouse game where improvements to one side automatically brings improvements to the other. It must be noted that a silver bullet type of solution to deobfuscation is rarely achievable and the necessity to implement custom passes to overcome specific types of limitations must be taken into account.
Lifting and optimizations
The ideal solution would be to have a widely-adopted representation for the code to be analyzed, where completeness and soundness in the handling of the semantic of the assembly instructions is preserved, and where static analysis passes are easy to develop.
All the major reverse engineering tools provide a custom intermediate representation with more or less the same set of information and capabilities. IDA Pro recently exposed the microcode [20] API, Ghidra exposes the pcode [21] API and Binary Ninja even exposes multiple intermediate representations [22] of the code that facilitate different strategies to analyze the binary instructions.
What the mentioned intermediate representations lack is a big community and a mature set of analysis passes included in their frameworks. That’s why LLVM-IR [23] is the perfect solution. In fact the LLVM [24] compiler suite offers an intermediate representation called LLVM-IR which is at the core of the many analysis and optimization passes implemented by the development team over the years. The outcome of this is a single static assignment format, that provides a complete set of API to inspect and manipulate the intermediate representation and that is provided with a rich documentation to rely on, which perfectly meets our needs.
The missing link is how do we move from the assembly code to LLVM-IR, and that’s where a lifting tool like Remill [25] can help us. At the moment it supports the lifting of the x86, amd64 and aarch64 machine code and has a particular focus on the semantic correctness of the instructions. It also provides a small but valuable set of API to ease some tasks that are common during the LLVM-IR translation, inspection and manipulation phases.
LLVM is constantly improving, adding new optimizations and analysis passes that are going to be properly tested and added to the already exposed features, guaranteeing high implementation standards used by hundreds of projects every day. In particular, from a static analysis and deobfuscation point of view, it’s convenient to be able to rely on the many exposed passes and features, like:
- Constant folding: to propagate unoptimized or unfolded constants.
- Dead code elimination: to remove useless instructions and basic blocks.
- Peephole optimization: to match known patterns and easily add new ones.
- Loop (un)rolling and analysis: to have information and manipulate the loops.
- Module and function pass managers: to develop custom optimization passes.
It’s worth mentioning that projects like Souper decided to rely on the LLVM-IR for their superoptimization and synthesis implementation, exposing an LLVM pass that can be easily integrated in an existing optimization pipeline or caching mechanisms to improve the optimization speed.
Souper is also relying on SMT solvers like z3 [26], STP [27], Boolector [28], CVC4 [29] to prove the equivalence of the inferred optimizations, which come in hand when dealing with opaque predicates [30] or the implementation of exploration strategies like SAGE [31].
SATURN
The idea of developing SATURN is strictly related to the lack of a framework that uses LLVM-IR as a core component of its analysis and optimization steps. In fact, as stated in the Obfuscation evolution section, most of the modern obfuscators are relying on LLVM (and its intermediate representation LLVM-IR) to apply their modifications to the original code, so it makes sense to handle the problem at the same conceptual level.
Moreover, less advanced or older obfuscators are heavily relying on code deoptimization strategies (e.g. constant unfolding, junk code insertion) or using pattern-based substitutions (e.g. peephole deoptimization), problems that can be trivially solved out-of-the-box by modern optimizing compilers like LLVM.
Finally, the design choice of using an intermediate representation for the deobfuscation tasks is certainly not new (e.g. as previously stated almost every modern reverse engineering tool is exposing one or more custom intermediate languages), but the amount and quality of the analysis and optimization passes included in LLVM and the existence of academic tools like Souper or KLEE qualify LLVM-IR as the perfect choice.
Engine description
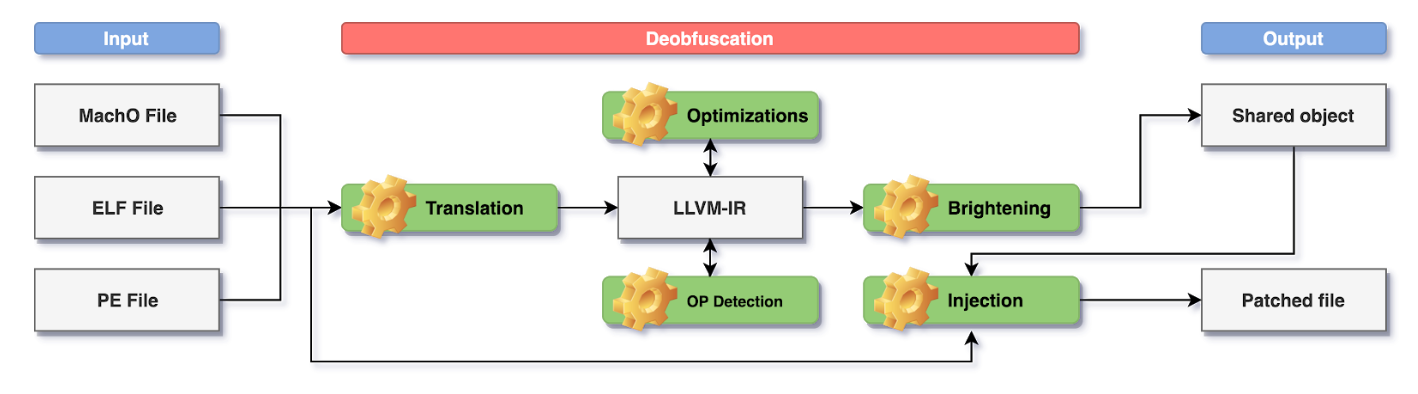
As can be seen in Figure 4, the high level implementation of SATURN can be divided into three main steps:
- The input is going to be a MachO, ELF or PE executable file which is going to be parsed by LLVM to collect information about the bitness, image base, architecture and available sections. The user needs to provide the addresses of the functions to be recovered and deobfuscated.
- The deobfuscation step consists in the lifting from the machine code to LLVM-IR, recovery of the functions’ CFGs, detection of the opaque predicates and of the optimization and brightening of the recovered code.
- The output is going to be the deobfuscated code recompiled for the same architecture of the input file. It can be a shared object containing the exported recovered functions or, if possible, the recovered code is going to be injected in the original input file. For manual analysis purposes it’s also possible to dump the SMT representation of the possible opaque predicate expressions and the LLVM-IR representation of the recovered functions. It’s worth noting that the output LLVM-IR module can be compiled by an LLVM backend for an architecture which is different from the input one, with obvious limitations related to architecture-specific instructions. As an example, think of an input binary using the Intel x64 instruction set with extension SSE4 [32] which is supported only by processors released after April 2008: LLVM could be leveraged to recompile the output LLVM-IR for older Intel x64 processors without support to SSE4.
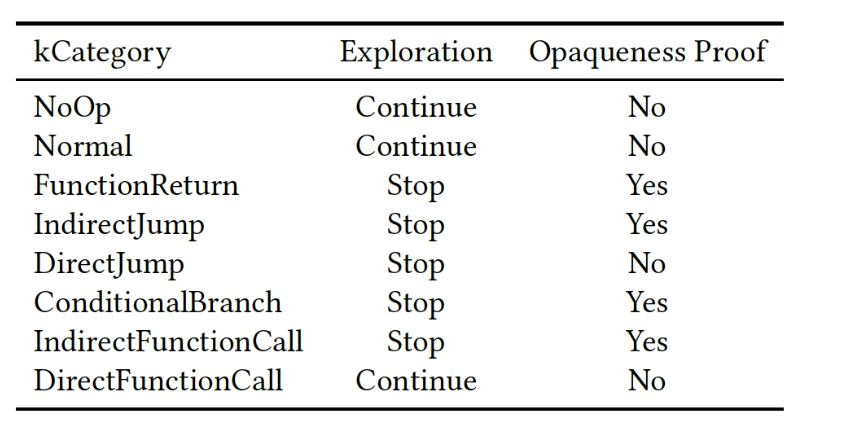
The deobfuscation step is the core of SATURN and can be further detailed as follows:
- Translation: Remill has been integrated at this step to translate the instructions of each basic block (a sequence of machine code ending with a control flow instruction) of the obfuscated function.
- Optimizations: at this point the LLVM-IR of each basic block is heavily optimized using standard LLVM optimizations and default Souper optimizations.
- Opaque predicates detection: the SMT solvers integrated in Souper are used at this step to prove the opaqueness of the control flow instructions found at the end of each recovered basic block, as can be seen in Figure 5. Namely, some protectors are using opaque conditions for the conditional jumps that always evaluate to either true or false, and this step is necessary to avoid the exploration of unreacheable basic blocks. Then the address(es) of the next block(s) are computed. At the current state SATURN offers some command line options to tweak the amount of information to be used during the opaqueness tests. As an example, some protectors are spreading their opaque predicate expressions over multiple basic blocks, so SATURN offers an option to select the amount of basic blocks to be considered during the evaluation.
- Control flow graph reconstruction: the exploration algorithm which is currently integrated is iteratively recovering new basic blocks, trying its best to detect the opaque predicates. Every time a known block is re-discovered during the exploration a new opaqueness test is executed to make sure the opaqueness of the block is updated accordingly. Loops and switch-cases are detailed later because they may be crafted in specific ways to hinder a proper CFG exploration.
- Brightening: it’s probably the most important step executed by SATURN and its goal is to reshape the code to make it more readable and understandable for humans. It’s particularly important because the LLVM-IR obtained by the Remill’s lifting process is using a set of structures to keep the generality of the code, but that hinder proper optimizations and readability. The current implementation provides a set of analysis steps to identify the input arguments (register and stack based) and the local stack slots used by the function. The stack analysis steps also include a stack propagation algorithm, which, aided by the concretization of the stack pointer, is fundamental to optimize the read and write accesses to the local variables and improves the detection of the stack-based function arguments.
- Injection: The detection of the stack slots and of the original signature of the obfuscated function, following the target ABI calling convention, is also fundamental to guarantee the best output LLVM-IR code. The recovery of the original function signature enables a proper injection of the deobfuscated code into the input binary. Anyhow, even if the signature detection fails, SATURN implements a context-switch injection mechanism that permits the injection of the deobfuscated code which is still relying on the Remill’s internal structures.
The main idea behind SATURN is to be able to use strong and correct optimizations and to rely on an intermediate representation (LLVM-IR) which preserves the correctness of the semantic while being easier to work with (compared to machine code). In fact the LLVM-IR can be used to reason symbolically (e.g. proving symbolic expressions via SMT solvers), but also concretely (e.g. relying on the LLVM JIT API or concretizing the variables that represent the general purpose registers).
As shown in the Static analysis approaches section, all the mentioned static analysis techniques can be easily implemented at an intermediate representation level, which means that SATURN‘s reliance on LLVM-IR makes it ready out-of-the-box for such implementations. It’s not a case that tools like Souper or KLEE [33] are also basing their program synthesis and symbolic execution implementations on LLVM-IR.
Symbolic execution with KLEE
Another interesting use-case for the capability to recover the LLVM-IR version of a machine code function is the possibility to use the symbolic execution engine implemented by KLEE. In fact, KLEE is a symbolic virtual machine implemented on top of the LLVM infrastructure. But, differently from the symbolic engines implemented by Angr [34], Triton [35] or miasm [36] that work at the machine code level, it needs a source code to insert its instrumentation calls. The API calls are used to specify which variables or buffers are meant to be considered symbolic and to give additional information about them, so at a later step they can be handled accordingly by the KLEE internal engine.
A similar idea has been properly detailed in a research tool called KLEE-Native [37], where a trace of the program is lifted to LLVM-IR. SATURN could enable the analysis of entire functions without the need to record an execution trace, like if it was happening at the source code level.
Limitations and improvements
Whoever worked on attacking obfuscated code before knows that there isn’t a generic solution for each and all the obfuscation techniques. Usually, generic approaches can only produce generic results, and cannot really break entire protectors or obfuscators on their own in a standalone fashion. SATURN is in fact meant to offer a good amount of automation during the analysis task (e.g. to handle common obfuscation schemes), without sacrificing the manual intervention of the reverse engineer (e.g. implementation of custom passes). As an example, one protector may require a custom CFG exploration strategy or a custom handling of the opaque predicates or MBA expressions.
Limitations
At the current state SATURN suffers from the current limitations:
- Unimplemented opcodes: Remill has a great coverage of many x86, amd64 and aarch64 instructions, but some are missing and found in real commercial protectors. A proper implementation of the missing lifting step, that preserves the proper semantic, is required to properly use the tool. During the development of SATURN some bugs in the lifting of some instructions have been fixed, guaranteeing proper handling of known commercial protectors.
- Switch-cases: Souper’s range analysis and an SMT solver approach are able to identify the range of possible addresses in a switch-case construct, but some protectors are using only a subset of the possible values, so an ad-hoc switch-table identification and parsing may be required to properly explore all the switch destinations.
- Anti-DSE tricks: the research at [12] is proposing hardened versions of the FOR anti dynamic symbolic execution trick. At the moment of writing, LLVM is limited in the loop analysis that can be done in regard to this hardened technique, so the instructions implementing the FOR structure may persist in the deobfuscated version of the recovered function.
- MBA opaque predicates: opaque predicates based on irreducible MBA expressions or unprovable formulas may lose the precision during the exploration phase. This may lead to the discovery of unreacheable basic blocks that may persist in the deobfuscated version of the recovered function.
Improvements
Excluded the limitations strictly related to the lack of features, bugs or performance in the tools on which SATURN is relying, the following are some of the planned improvement:
- Plugin system: to let users implement their own optimization and analysis passes. This could be used to devirtualize a virtualization-based protector, or to handle MBA expressions with synthesis approaches like Drill&Join.
- Stack propagation: as mentioned before, at the moment the stack optimization is achieved through the concretization of the stack pointer, although a fully symbolic approach is in development.
- Aarch64 support: given that Remill supports the lifting of aarch64 machine code, it would be ideal to integrate it in SATURN to extend the analysis and optimization capabilities to Android and iOS native libraries.
- Exploration strategies: to be able to adopt a different exploration strategy based on the control flow obfuscation used by the target. For example implementing a customized version of SAGE would enable an SMT solver based exploration.
Acknowledgements
I would like to thank Peter Garba (from the Thales DIS Cybersecurity group) who acted as the leader of the research done around SATURN and as an awesome LLVM mentor. I would also like to thank Roman Rohleder, for taking the time to proofread the paper and contributing with his knowledge during countless discussions. A big thanks to my colleagues at Zimperium that took the time to read the paper at its release date and provided valuable feedback.
References
[01] https://arxiv.org/abs/1909.01752
[03] https://o-llvm.org/
[04] https://github.com/andrivet/ADVobfuscator
[05] https://strong.codes/ (now unreachable)
[06] https://blog.quarkslab.com/obfuscating-java-bytecode-with-llvm-and-epona.html
[07] https://www.guardsquare.com/en/blog/dexguard-ndk-add-on-20
[08] https://www.guardsquare.com/en/products/ixguard
[09] https://github.com/rednaga/APKiD/blob/master/apkid/rules/elf/obfuscators.yara
[10] https://tigress.wtf/
[12] https://arxiv.org/abs/1908.01549
[13] https://www.hexblog.com/?p=1248
[14] https://arxiv.org/abs/1711.04422
[15] http://stoke.stanford.edu/
[16] https://www.usenix.org/system/files/conference/usenixsecurity17/sec17-blazytko.pdf
[17] https://link.springer.com/chapter/10.1007/978-3-319-17822-6_13
[18] https://www.sciencedirect.com/science/article/pii/S0167404817301475
[20] https://www.hex-rays.com/products/ida/7.1/index.shtml
[21] http://ghidra.re/courses/languages/html/pcoderef.html
[22] https://docs.binary.ninja/dev/bnil-llil.html
[23] https://llvm.org/docs/LangRef.html
[24] http://llvm.org/
[25] https://github.com/lifting-bits/remill
[26] https://github.com/Z3Prover/z3
[28] https://boolector.github.io/
[30] https://en.wikipedia.org/wiki/Opaque_predicate
[31] https://patricegodefroid.github.io/public_psfiles/ndss2008.pdf
[32] https://en.wikipedia.org/wiki/SSE4
[34] https://angr.io/
[35] https://triton.quarkslab.com/
[37] https://blog.trailofbits.com/2019/08/30/binary-symbolic-execution-with-klee-native/


